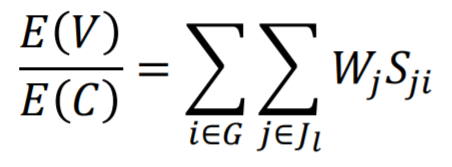
I build tools for people
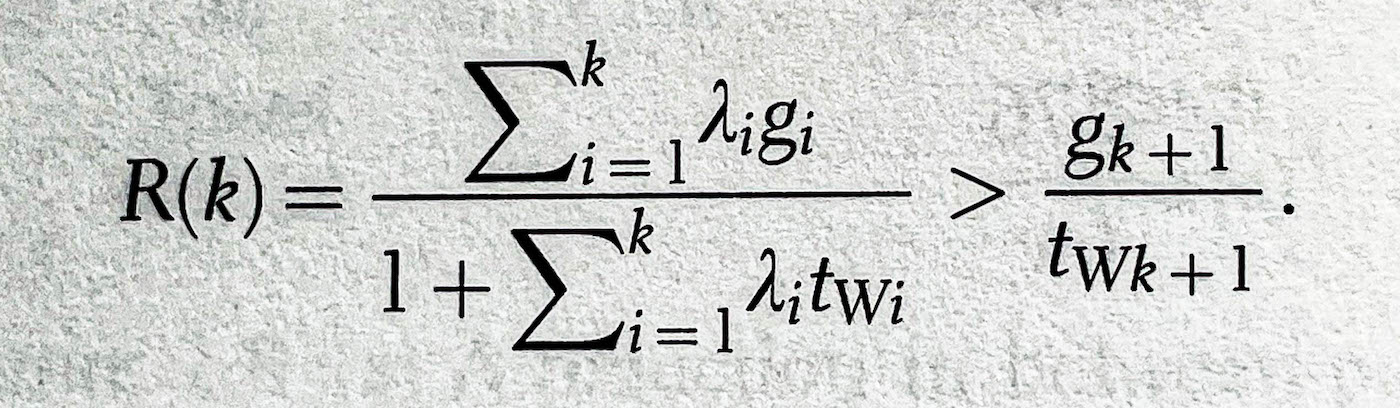
See the discussion of this post on Hacker News.
Researchers have been developing a theory, Information Foraging Theory (IFT), of how people seek information, whether it be on the web, in a filing cabinet, or even in source code. It follows a metaphor that stems from animals looking for food in the wild.
A person, known as the predator, seeks information, known as the prey, in an information environment made up of patches, which could be code files, program output, log data, a stack trace, debugger information, etc. The predator navigates within and between patches using links (e.g., a shortcut to jump to a function's definition or a button in a menu) that have some cost (e.g., effort and time) until the predator's information goals are satisfied.
In a patch there are information features (e.g., words and graphics), which may include the prey. Each information has a value to the predator (possibly a zero value!) and a cost (e.g., the time to process the information). Some information features act as cues that provide a clue as to what a link may lead to.
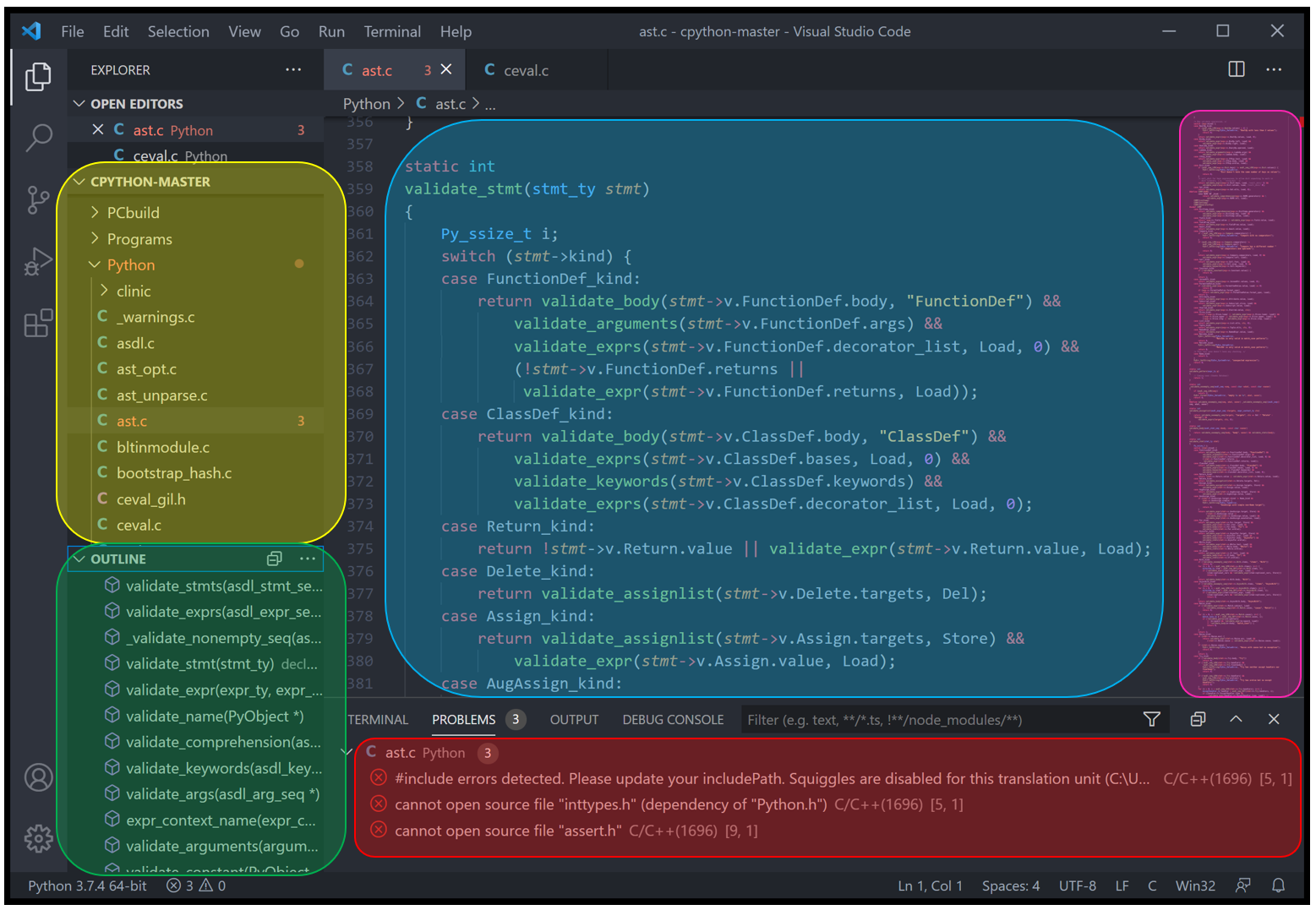
Above you can see a screenshot of VS Code with some of the information patches annotated. The editor displays a lot of information. The annotations are highlighting the file listing, an outline view of the current code file, a small region of a code file, the output from the compiler, and a minimap of the current file.
I can navigate within the current code file by scrolling or using Ctrl+F. I can navigate to other patches by clicking on other tabs, buttons, or invoking the Go to Definition shortcut. Furthermore, I could produce new patches by performing a search that will yield a listing of results or by enabling the debugger to display runtime information.
The predator always has three choices: forage within a patch, navigate between patches, or enrich the environment. Foraging within the patch involves processing the information features at their current location. Navigating between patches involves traversing a link to go to a different patch that can hopefully satisfy the predator's goals. The third option involves the predator changing the environment, such as bookmarking a code location or performing a text search, which produces a new patch with search results.
The predator is always trying to maximize the amount of information gained relative to the cost. Given that v is the value and c is the cost, then the optimal choice = max v⁄c.
However, the predator often does not know the value or cost of foraging, so they must make decisions based on their own estimations. That is described as selected choice = max E(v)⁄E(c).
These expected value and cost estimates are based on information scent, which is their perceived chance of finding relevant information based on information features and cues. At any given point, the predator is following the path with the highest scent to maximize the expected value gained while minimizing the cost of foraging.
How predators evaluate links is formalized as:
The predator is seeking G and has access to L links. Each link has a set of associated cues Jl where Wj is the amount of attention given by the predator, and Sji is the scent.
If you want to know more about the formal theory, take a look at Pirolli's book, Information Foraging Theory: Adaptive Interaction with Information (Amazon).
Over a dozen studies have been published in the last fifteen years that look at IFT in the context of software development. Below are summaries and links to papers that I found particularly interesting:
There are endless implications for development tools from these studies. In fact, I've recently written about a tool for navigating code (see Navigate your code like it's 2021) and a tool for viewing older versions of code (see Why is it so hard to see code from 5 minutes ago?).
There is much more work to do. Happy foraging!